Richard Sutton's "Bitter Lesson" lays out a hard truth at the heart of modern AI: Not the clever injection of human knowledge, but scalable learning and search algorithms are what deliver lasting breakthroughs. Now, a new paper from Sutton and David Silver builds on this thesis—sketching out a far-reaching vision for AI agents that advance solely through action and feedback.
In 2019, Sutton published a brief essay that's become one of the most influential touchstones in current AI research. His central argument: The biggest leaps in AI haven't come from human insight, but from machines that, with massive compute and minimal built-in knowledge, learn to improve themselves.
Humans, Sutton argues, tend to force their own intuition into algorithms—but eventually, it's the systematic, data-driven approaches that win. This "bitter lesson" is now foundational in reinforcement learning (RL)—the technology behind AlphaGo and, more recently, the new wave of "reasoning" language models.
Five years later, Sutton (a Turing Award winner and head of DeepMind's Alberta lab), along with his former PhD student and Deepmind RL lead David Silver, has published a new essay: "Welcome to the Era of Experience."
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
The paper calls for a major shift—from building AI on top of human knowledge to building systems that improve by acting in the world and learning from feedback. The vision: AI that evolves on its own terms, not just by remixing what people already know.
Moving beyond human-generated data
Sutton and Silver point out that today's generative AI—such as large language models—are built almost entirely on human data: books, websites, forums, all scraped and repackaged. These models can do many things, but there's a ceiling: The industry eventually runs out of high-quality human data, and some breakthroughs are simply beyond what humans have figured out so far. AI that learns by imitation will become competent, but it won't be truly creative.
Their argument is that we need agents that are always learning, always adapting. Instead of being trained once and then left static, future AIs should live in a never-ending stream of experiences, adjusting to their environment over months or years—much like people or animals. Every new action, every experiment, is a fresh source of data. Unlike human-written text, experience is limitless.
They frame this as a fundamental shift: from fixed data sets to ongoing interaction, from supervised learning to open-ended exploration. In this framework, intelligence emerges through behavior and adaptation, not from prompts or datasets. If successful, the approach could lead to substantial advancements in AI capabilities.
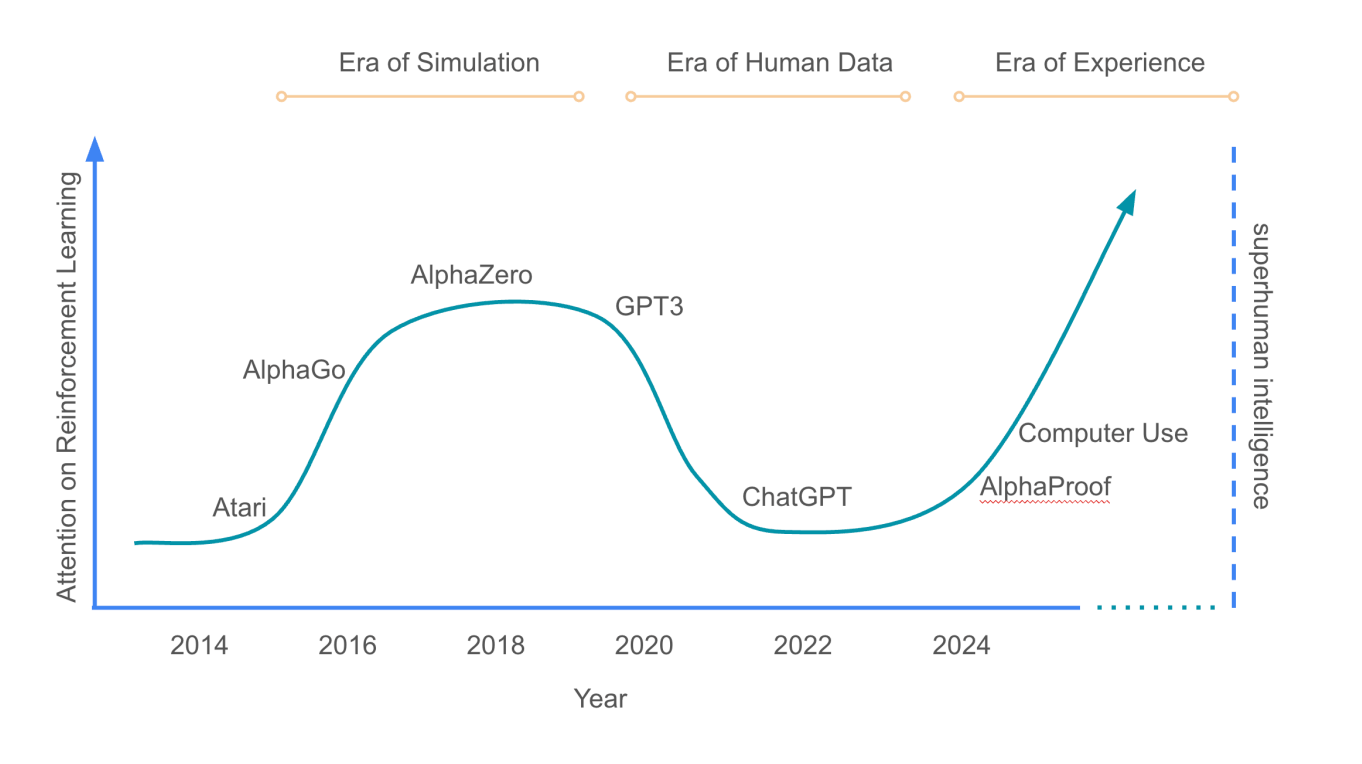 According to Sutton and Silver, AI has gone through three distinct eras: simulation, human data, and now experience. RL's popularity has surged and dipped, peaking around AlphaZero and coming back with AlphaProof. Ultimately, RL could be the key to reaching superhuman AI. | Image: Sutton, Silver
According to Sutton and Silver, AI has gone through three distinct eras: simulation, human data, and now experience. RL's popularity has surged and dipped, peaking around AlphaZero and coming back with AlphaProof. Ultimately, RL could be the key to reaching superhuman AI. | Image: Sutton, SilverTraining AI with World Models
The paper describes how classic RL methods can be combined with newer techniques. One example is AlphaProof, a DeepMind system designed for formal mathematics. It merges a pre-trained language model with the AlphaZero reinforcement learning algorithm. After learning briefly from human proofs, AlphaProof was able to generate over 100 million additional proof steps through autonomous exploration—outperforming systems trained solely on curated human data.
Recommendation

Sutton and Silver want to extend this to the real world: They describe health assistants that analyze sleep patterns and adjust advice, or educational agents that track years of student progress, or even scientific AIs running their own experiments.
The key is that these agents would get feedback not just from human ratings, but from measurable signals in the environment—resting heart rate, CO₂ levels, test results. Human feedback could still play a role, but only if it's grounded in the consequences of an action—like how a cake tastes, or how you feel after a workout.
When it comes to machine "thinking," the authors argue for breaking with current practice. Language models try to mimic human reasoning through things like chain-of-thought prompts, but that just bakes in human errors and biases.
Instead, agents should build their own internal "world models"—simulations they use to predict the results of their actions. This makes real planning possible, not just clever language tricks. They see future agents moving through intermediate steps: calling APIs, executing code and observing feedback, all as scaffolding toward genuine autonomy.
They also see this "Era of Experience" as a return to the RL roots that have been overshadowed by the success of large language models and RLHF. Long-term learning and planning will require tools like temporal abstraction, exploratory behavior, and dynamic value functions—all classic RL territory.
The authors argue that this shift is already underway. Examples include digital agents that interact with user interfaces, RL systems tackling open-ended tasks, and AI systems increasingly connected to real-world data streams. One such agentic system, the o3 model used for OpenAI's Deep Research, was trained on a "wide range of complex browsing and reasoning challenges" using reinforcement learning techniques.
More autonomy means more responsibility
With greater autonomy comes both opportunity and risk. Agents capable of long-term planning and adaptation could acquire skills traditionally considered uniquely human. This could mean that such systems will be more difficult to control and tune than conventional software.
But Sutton and Silver suggest that the very nature of continuous interaction may improve safety. Agents that are embedded in real-world environments could learn to recognize unintended consequences and adjust accordingly. Reward functions could be refined through user feedback. And real-world constraints—like medical studies—would naturally slow down reckless progress.
Sutton and Silver note that we already have the technical ingredients: enough compute, simulation environments, and RL algorithms. While "experiential intelligence" is still a young field, the tools are there, and the researchers are calling for the AI community's willingness to adapt to a new paradigm.
Their takeaway is blunt: experience should not be treated as an afterthought—it should serve as the foundation for all AI development. Sutton and Silver argue that future breakthroughs will come from systems that learn to think independently, rather than merely replicating human ideas.
For more on the topic, Silver explains the paper's ideas in a Google DeepMind podcast.
Recognizing the limits of language models
The idea that pure language modeling won't get us all the way to superhuman AI has, quietly, become mainstream in the industry. No matter how much text is used for training, models still struggle with basic common sense and the ability to generalize across tasks.
Leading voices are moving in this direction. Ilya Sutskever, OpenAI co-founder and ex-chief scientist, is now working on alternative paths to superintelligence at his new startup "SSI." Sutskever was already talking about reaching "peak data" back in 2024, calling for new approaches. Meta's Yann LeCun is pushing for new architectures beyond language models, and Sam Altman (OpenAI CEO) said in 2023 that language alone just isn't enough for AGI and beyond.
One promising direction is the aforementioned "world model" concept—systems that can process not just language, but also sensory and motor experiences, building in a sense of causality, space, time, and action. The catch: major breakthroughs here are still unreachable.
Perhaps the biggest challenge for RL outside of specific domains like a board game or certain math tasks is generalization, especially for problems without a clear right or wrong answer. The latest reasoning LLMs are much stronger at math than traditional models, but they don't necessarily outperform on knowledge or creative tasks.

