One of the most compelling results in recent o3 benchmarks comes from its performance on long-context tasks.
With support for up to 200,000 tokens, o3 is the first model to achieve a perfect 100 percent on the Fiction.live benchmark using 128,000 tokens—that’s roughly 96,000 words. For any language model working with sprawling narratives or massive documents, this is a significant leap forward. The only model that comes close is Google’s Gemini 2.5 Pro, which scored 90.6 percent, while o3-mini and o4-mini trail well behind.
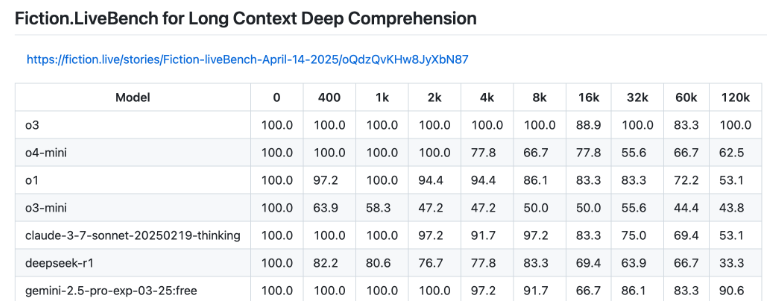 Image: Fiction.live (Screenshot)
Image: Fiction.live (Screenshot)The Fiction.LiveBench test is designed to see how well models can fully understand and accurately reproduce complex stories and their contexts, even as the text stretches to prodigious lengths.
Meta’s Llama 4, for example, advertises a context window of up to ten million tokens—a number that sounds impressive on paper. But in practice, it’s barely useful for anything beyond simple word searches, and it falls short when it comes to meaningful long-form comprehension.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
It’s not just Llama 4. Across the board, many models underperform on true long-context understanding, turning these enormous context windows into more of a marketing gimmick than a genuine capability. At worst, they give users the illusion that the model is digesting the entire document, when in reality, much of the text goes largely unconsidered—a shortcoming highlighted by multiple studies.
For anyone with real-world needs that require consistent, deep performance over massive inputs, o3 is now the clear standard-bearer.