- Last updated September 6, 2024
- In AI News
The Reflection-Tuning technique allows Reflection 70B to detect and correct its own mistakes before finalising an answer.

Illustration by Illustrated by Nikhil Kumar

Matt Shumer, co-founder and CEO of AI writing startup HyperWrite recently launched a new model called Reflection 70B.
I'm excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week – we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on ⬇️: pic.twitter.com/kZPW1plJuo
The model has emerged as a leading open-source language model, outperforming top closed-source models like OpenAI’s GPT-4o and Anthropic’s Claude Sonnet 3.5. The model, developed using a novel technique called Reflection-Tuning, showcases significant improvements in benchmark tests, including MMLU, MATH, IFEval, and GSM8K.
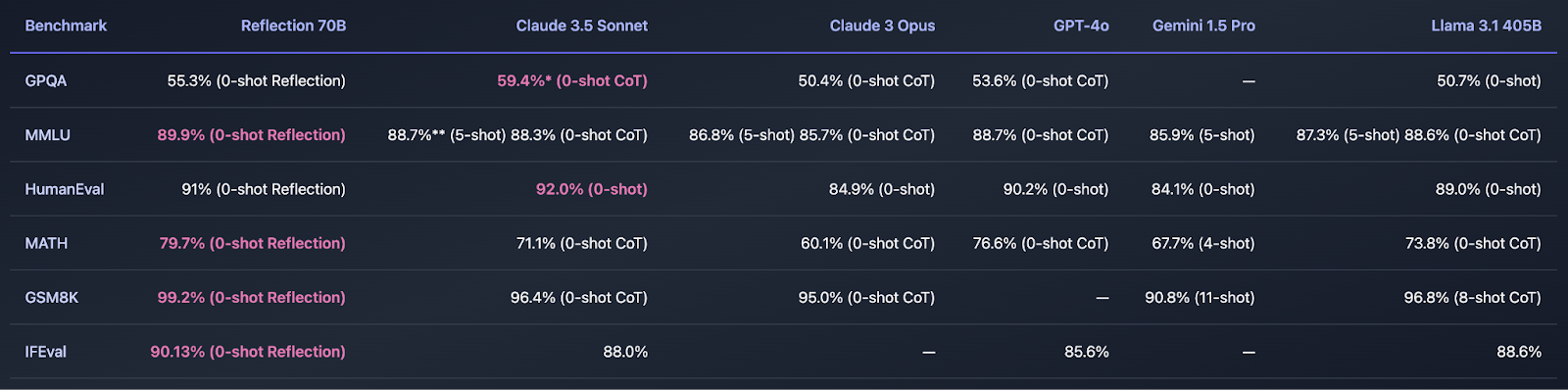
The Reflection-Tuning technique allows Reflection 70B to detect and correct its own mistakes before finalising an answer. This advancement aims to address the common issue of model hallucinations and improve reasoning accuracy.
The model outputs its internal reasoning in <thinking> tags and final answers in <output> tags, with additional <reflection> tags used for correcting any detected errors.
Currently, Reflection 70B holds the top position in several benchmarks and demonstrates superior performance over GPT-4o and Llama 3.1 405B. The upcoming Reflection 405B model, expected next week, is anticipated to further elevate the standard for LLMs globally.
This is second model this week outperforming GPT-4o and Claude Sonnet 3.5
Alibaba recently released Qwen2-VL, the latest model in its vision-language series. The new model can chat via camera, play card games, and control mobile phones and robots by acting as an agent. It is available in three versions: the open source 2 billon and 7 billion models, and the more advanced 72 billion model, accessible using API.
The advanced 72 billion model of Qwen2-VL achieved SOTA visual understanding across 20 benchmarks. “Overall, our 72B model showcases top-tier performance across most metrics, often surpassing even closed-source models like GPT-4o and Claude 3.5-Sonnet,”said the company in a blog post, saying that it demonstrates a significant edge in document understanding.
![]()
Siddharth Jindal
Siddharth is a media graduate who loves to explore tech through journalism and putting forward ideas worth pondering about in the era of artificial intelligence.



Association of Data Scientists
Tailored Generative AI Training for Your Team
Upcoming Large format Conference
Sep 25-27, 2024 | 📍 Bangalore, India
Download the easiest way to
stay informed


Subscribe to The Belamy: Our Weekly Newsletter
Biggest AI stories, delivered to your inbox every week.
Rising 2024 | DE&I in Tech Summit
April 4 and 5, 2024 | 📍 Hilton Convention Center, Manyata Tech Park, Bangalore
Data Engineering Summit 2024
May 30 and 31, 2024 | 📍 Bangalore, India
26 July 2024 | 583 Park Avenue, New York
MachineCon GCC Summit 2024
June 28 2024 | 📍Bangalore, India
Nov 21-22 2024 | 📍Santa Clara Convention Center, California, USA
September 25-27, 2024 | 📍Bangalore, India
![]()
Our Discord Community for AI Ecosystem, In collaboration with NVIDIA.


