‘My synthetic data cost goes down 30x’



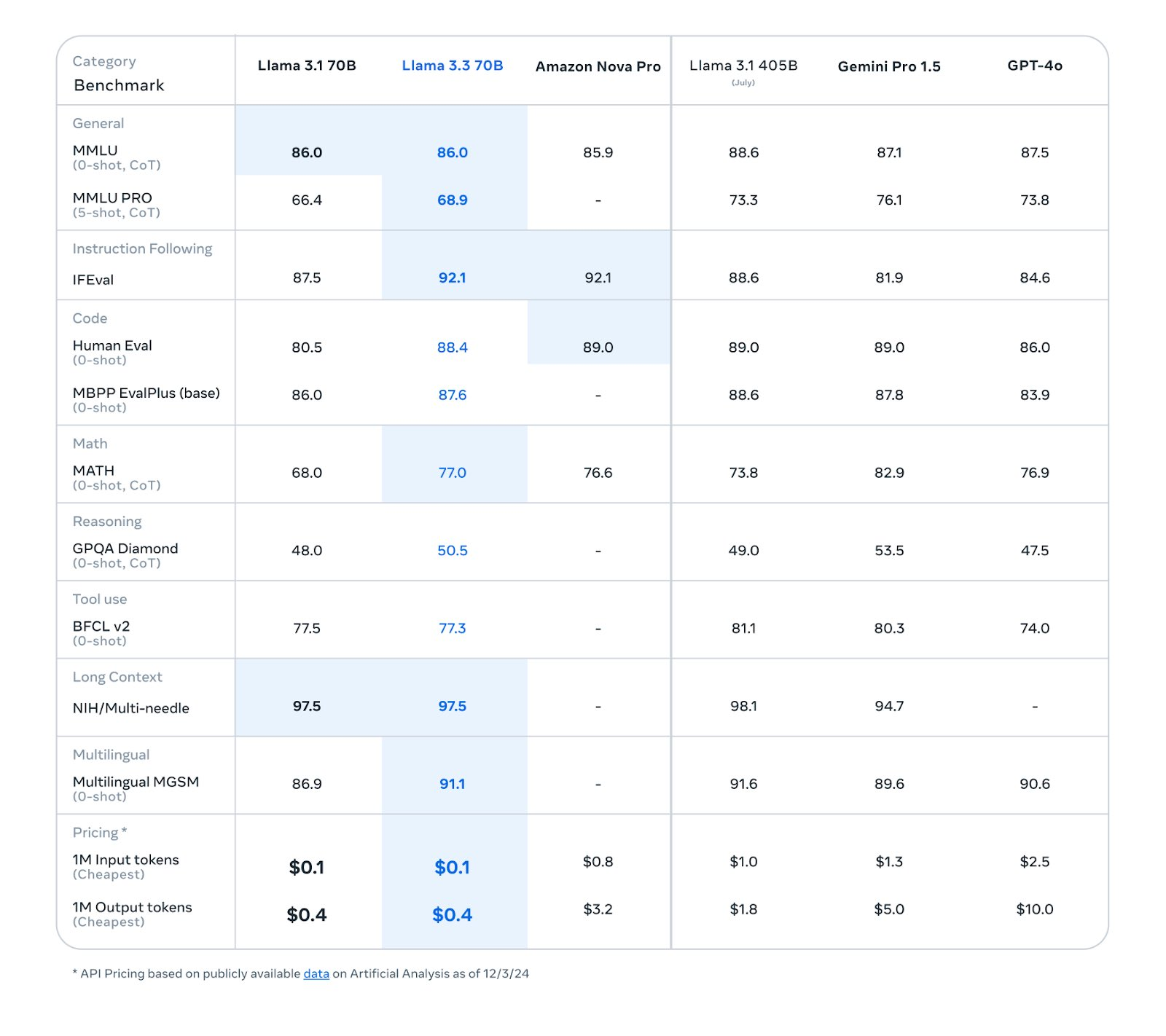
Meta today unveiled Llama 3.3, a multilingual LLM to redefine AI’s role in synthetic data generation. Featuring 70 billion parameters, Llama 3.3 is as performant as the previous 405B model yet optimised for efficiency and accessibility.
Its multilingual output supports diverse languages, including Hindi, Portuguese, and Thai, empowering developers worldwide to create customised datasets for specialised AI models.
“As we continue to explore new post-training techniques, today we’re releasing Llama 3.3 — a new open source model that delivers leading performance and quality across text-based use cases such as synthetic data generation at a fraction of the inference cost,” shared Meta, on X.
Fuels Synthetic Data Generation
Developers can now use its expanded context length of 128k tokens to produce vast and high-quality datasets, addressing challenges like privacy restrictions and resource constraints.
Meta’s AI chief Yann LeCun previously said that this capability enables innovation in low-resource languages, a sentiment echoed by Indian entrepreneur Nandan Nilekani. “India should focus on building small, use-case-specific models quickly,” Nilekani said, highlighting Llama’s pivotal role in generating tailored training data for Indic language models.
The success of such approaches is evident in projects like Sarvam AI’s Sarvam 2B, which outperforms larger models in Indic tasks by utilising synthetic data generated with Llama.
Hamid Shojanazeri, an ML engineer at Meta, said synthetic data generation solves critical bottlenecks in domains where collecting real-world datasets is too costly or infeasible. “Synthetic data is vital for advancing AI in privacy-sensitive areas or low-resource languages,” he added. With its RLHF tuning and supervised fine-tuning, Llama 3.3 produces instruction-aligned datasets for tasks requiring high precision.
Indic startups like Sarvam AI and Ola Krutrim have already reaped the benefits of Llama’s capabilities. Sarvam AI’s 2B model trained on 2 trillion synthetic Indic tokens demonstrates how such data can efficiently train smaller, purpose-built models while retaining high performance.
“If you look at the 100 billion tokens in Indian languages, we used a clever method to create synthetic data for building these models using Llama 3.1 405B. We trained the model on 1,024 NVIDIA H100s in India, and it took only 15 days,” said Sarvam AI chief Vivek Raghavan in an interview with AIM.
Similarly, Llama 3.3’s multilingual support and scalability make it indispensable for bridging the data divide in underrepresented languages.
Llama 3.3’s ability to support synthetic data generation extends beyond niche use cases, fostering broader adoption among developers, educators, and businesses. “By reducing the cost of producing high-quality training data, Llama accelerates innovation globally,” said Ahmad Al-Dahle, Meta’s VP of Generative AI.
As speculation about GPT-4.5 intensifies, Llama 3.3 has decisively stepped in to meet immediate developer needs. With its revolutionary approach to synthetic data generation and cost-effectiveness, it’s clear that Llama 3.3 isn’t just filling a gap—it’s setting a new standard.
“My synthetic data cost goes down 30x,” said Pratik Desai, co-founder at KissanAI, on X.
Laying the Groundwork for Llama 4
The release of Llama 3.3 fits squarely into Meta’s long-term AI strategy. As Zuckerberg revealed during Meta’s Q3 earnings call, the forthcoming Llama 4, set for early 2025, will introduce “new modalities, stronger reasoning, and much faster capabilities.” This suggests that synthetic data generation capabilities refined in Llama 3.3 could become even more robust in future iterations.
Meta’s VP Ragavan Srinivasan recently hinted at advancements in “memory-based applications for coding and cross-modality support” for future Llama models. The robust framework established by Llama 3.3’s synthetic data capabilities could be integral to these developments. By enabling developers to produce domain-specific training datasets, Meta positions itself as a critical enabler of innovation in both the private and public sectors.
Future Llama versions will likely support an even broader array of languages and specialised use cases. As synthetic data generation becomes central to AI development, tools like Llama Guard 3 and enhanced tokenisation methods will ensure safe, responsible usage.
For countries like India, where data creation in regional languages is critical, it offers an accessible pathway to developing culturally relevant AI solutions.
Globally, as Mark Zuckerberg mentioned, Meta’s next-generation data center in Louisiana promises to drive even more ambitious AI advancements: “We are in this for the long term, committed to building the most advanced AI in the world.”
[This story has been read by 2 unique individuals.]
![]()
Siddharth Jindal
Siddharth is a media graduate who loves to explore tech through journalism and putting forward ideas worth pondering about in the era of artificial intelligence.





Association of Data Scientists
GenAI Corporate Training Programs
India's Biggest Developers Summit
February 5 – 7, 2025 | Nimhans Convention Center, Bangalore
Download the easiest way to
stay informed



Subscribe to The Belamy: Our Weekly Newsletter
Biggest AI stories, delivered to your inbox every week.
February 5 – 7, 2025 | Nimhans Convention Center, Bangalore
Rising 2025 | DE&I in Tech & AI
Mar 20 and 21, 2025 | 📍 J N Tata Auditorium, Bengaluru
Data Engineering Summit 2025
May, 2025 | 📍 Bangalore, India
MachineCon GCC Summit 2025
June 2025 | 583 Park Avenue, New York
September, 2025 | 📍Bangalore, India
MachineCon GCC Summit 2025
The Most Powerful GCC Summit of the year
![]()
Our Discord Community for AI Ecosystem, In collaboration with NVIDIA.

