Quantization-aware training allows Google's latest models to run on local GPUs and even mobile devices.
With a specialized training approach, these new Gemma 3 variants can now run efficiently on consumer hardware—think gaming GPUs or even mobile devices—without taking a major hit in quality. For context, the original Gemma 3 models were built for high-performance setups using NVIDIA H100s and BFloat16 precision, keeping them mostly out of reach for everyday users.
The key to this shift is quantization, a process that drastically cuts memory usage. Both models and their checkpoints are now available on Hugging Face and Kaggle.
Quantization means storing weights and activations with fewer bits—often 8, 4, or even just 2—instead of the usual 16 or 32. This leads to smaller models that run faster, since lower-precision numbers are quicker to move and process.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
Reducing memory use through quantization-aware training
With Gemma 3, Google applies Quantization-Aware Training (QAT), a technique that introduces reduced-precision conditions during training. By simulating lower bit widths from the start, the model learns to adapt to these limits, minimizing the usual performance drop when running at lower precision.
The savings on memory are substantial. The 27B model, for example, drops from 54 GB of VRAM down to just 14.1 GB in int4 format. The 12B variant shrinks from 24 GB to 6.6 GB. Even the smaller models benefit: the 4B version comes in at 2.6 GB, while the 1B model needs only 0.5 GB.
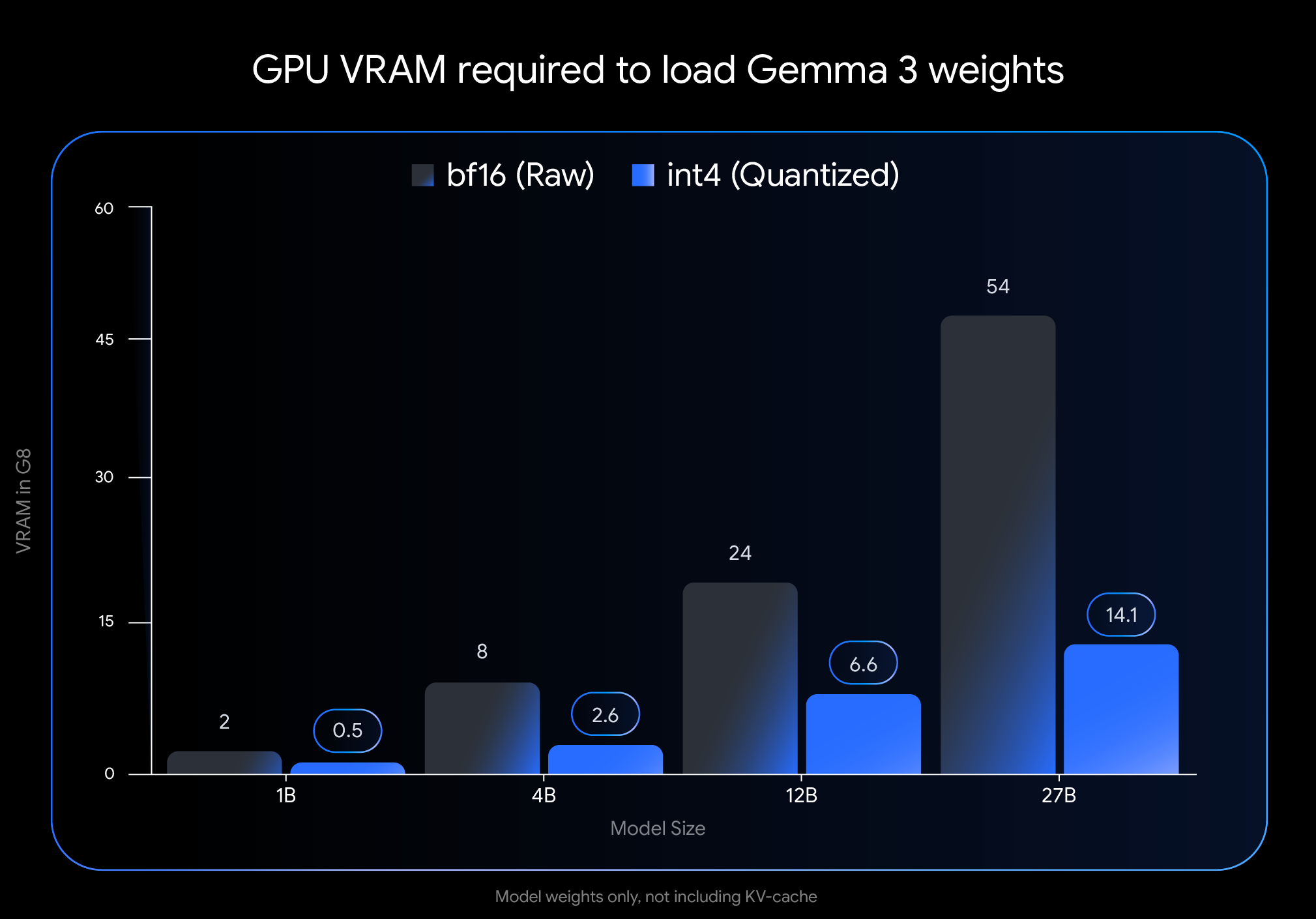 The quantization of the Gemma models leads to a dramatic drop in VRAM requirements. For example, while the 27B model needs 54 GB in its raw format, the quantized version runs at just 14.1 GB—with performance that, according to Google, remains comparable due to quantization-aware training. | Image: Google
The quantization of the Gemma models leads to a dramatic drop in VRAM requirements. For example, while the 27B model needs 54 GB in its raw format, the quantized version runs at just 14.1 GB—with performance that, according to Google, remains comparable due to quantization-aware training. | Image: GoogleGoogle claims that because of QAT, the models are "robust to quantization," a condition that typically results in some loss of model quality. However, the company has not released updated benchmark results to support that claim.
The models are compatible with common inference engines for integration into existing workflows. Native support is available for Ollama, LM Studio and MLX (for Apple Silicon), among others. Tools such as llama.cpp and gemma.cpp also offer support for the quantized Gemma models in GGUF format.
Beyond Google’s official releases, the community is also experimenting under the "Gemmaverse" banner—community variants that use post-training quantization to mix and match model size, speed, and quality.
Recommendation



