ElevenLabs' new Scribe model goes beyond basic transcription, interpreting non-verbal elements and speaker roles even at extreme speaking speeds.
The California startup, best known for voice synthesis and cloning, has now entered the speech-to-text market with this powerful new tool, available through their website and API.
John "Motormouth" Moschitta set a Guinness World Record in 1984 for speaking 586 words per minute. Although the record was broken in 1990, it still underlines Scribe's abilities. | Video: via ElevenLabs
Scribe offers accurate recognition across 99 languages, including previously underserved ones like Serbian, Cantonese, and Malayalam. In benchmarks using standard datasets like FLEURS and Common Voice, ElevenLabs reports that Scribe achieved lower word error rates than competing systems from Google, OpenAI, and Deepgram.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
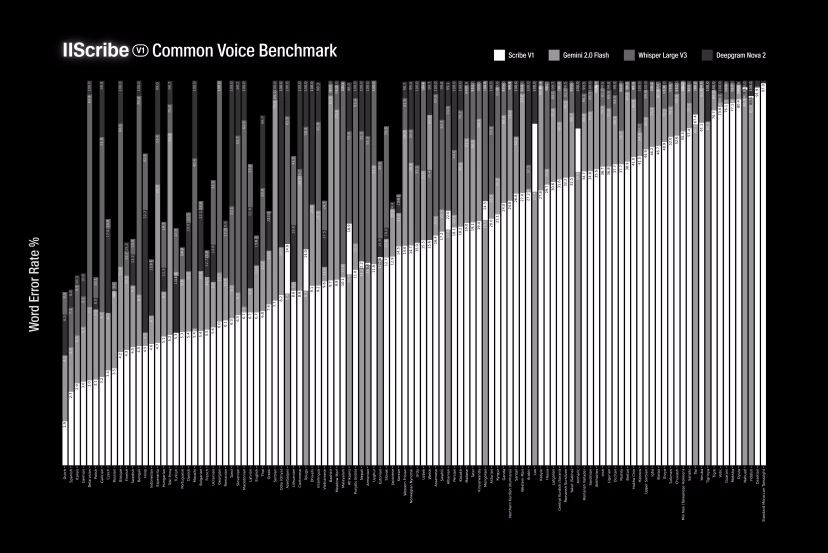 The chart compares word error rates (WER) across different speech recognition models in the FLEURS benchmark. Lower percentages on the vertical axis indicate better performance, with each horizontal group representing a different language. Colored bars within each language group show how individual models performed, with Scribe consistently showing the lowest error rates. | Image: ElevenLabs
The chart compares word error rates (WER) across different speech recognition models in the FLEURS benchmark. Lower percentages on the vertical axis indicate better performance, with each horizontal group representing a different language. Colored bars within each language group show how individual models performed, with Scribe consistently showing the lowest error rates. | Image: ElevenLabs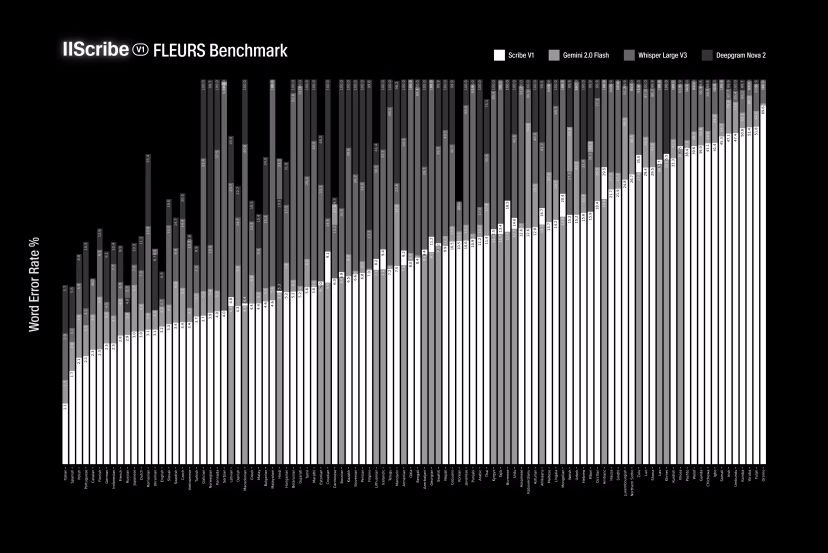 Image: ElevenLabs
Image: ElevenLabsIndependent testing by Artificial Analysis validates ElevenLabs' claims, showing that Scribe v1 achieves a 7.7 percent word error rate — approximately one percentage point better than the closest competing system.
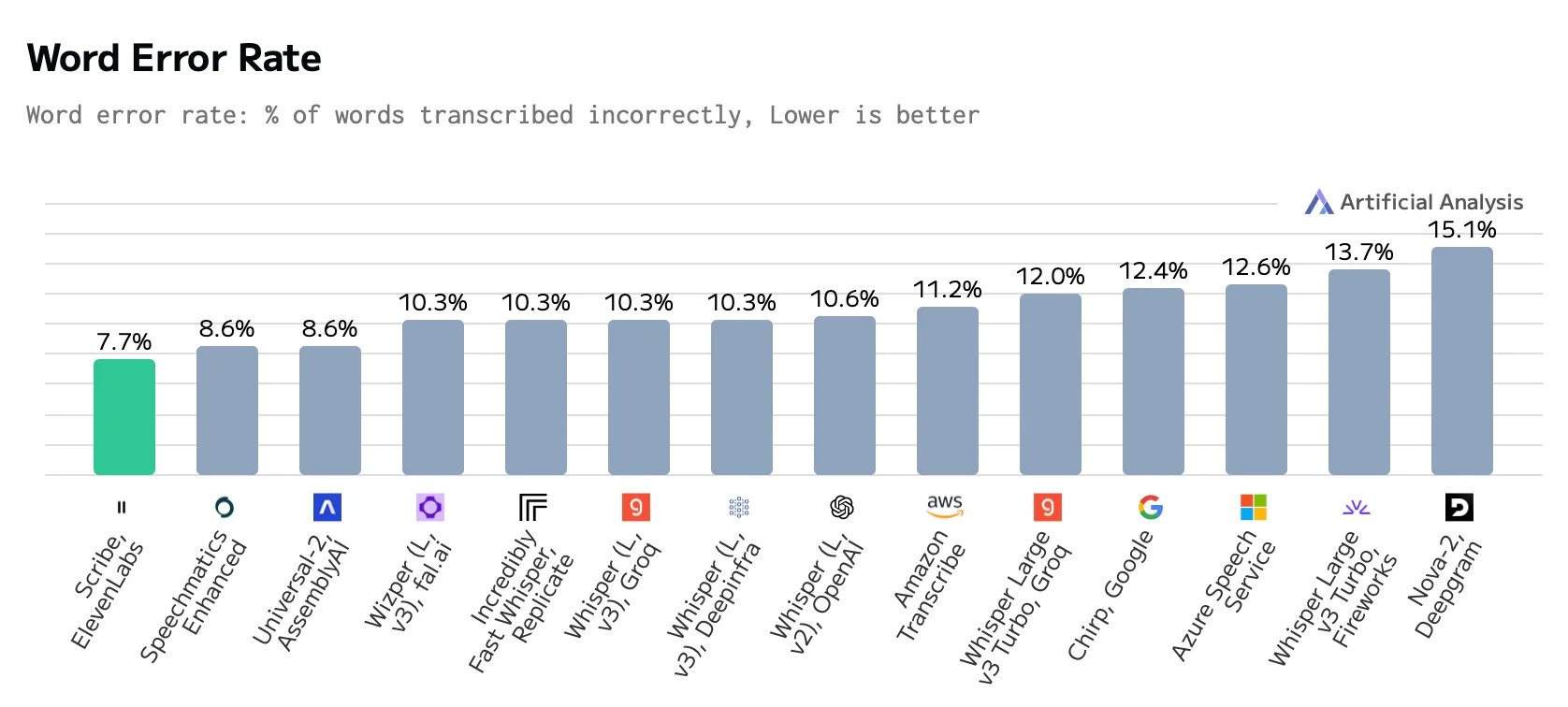 Scribe beats the previous best solution by just under one percentage point. | Image: Artificial Analysis
Scribe beats the previous best solution by just under one percentage point. | Image: Artificial AnalysisUnderstanding the full audio context
"Scribe doesn't just transcribe — it understands audio," says Flavio Schneider, lead researcher at ElevenLabs. According to Schneider, the system recognizes non-verbal elements like laughter, sound effects, music, and background noise while analyzing extended audio contexts for accurate speaker identification, even in challenging environments.
One of Scribe's standout features is diarization — the ability to automatically assign text to specific speakers. According to the documentation, the system can track and differentiate up to 32 distinct voices within a single recording.
The output includes detailed word-level timestamps and structured data through an API, opening up diverse applications. This makes the system equally valuable for creating automated documentation, generating subtitles, or analyzing customer service calls in busy call centers.
One hour costs 40 cents
An hour of audio transcription with Scribe costs $0.40, putting it in the same price range as OpenAI's Whisper. ElevenLabs is offering a 50 percent discount for the first six weeks after launch, with a low-latency version for real-time applications coming soon.
Recommendation

With Scribe, ElevenLabs is directly competing with established automatic speech recognition providers like Google, OpenAI, Deepgram, and AssemblyAI. Founded in 2022, the startup recently raised $180 million in a financing round and is now valued at $3.3 billion.


