- Last updated September 4, 2024
- In AI News
The advanced 72 billion parameter version of Qwen2-VL suprasses GPT-4o and Claude 3.5 Sonnet.


Alibaba recently released Qwen2-VL, the latest model in its vision-language series. The new model can chat via camera, play card games, and control mobile phones and robots by acting as an agent. It is available in three versions: the open source 2 billon and 7 billion models, and the more advanced 72 billion model, accessible using API.
The advanced 72 billion model of Qwen2-VL achieved SOTA visuals understanding across 20 benchmarks. “Overall, our 72B model showcases top-tier performance across most metrics, often surpassing even closed-source models like GPT-4o and Claude 3.5-Sonnet,” read the blog, saying that it demonstrates a significant edge in document understanding.
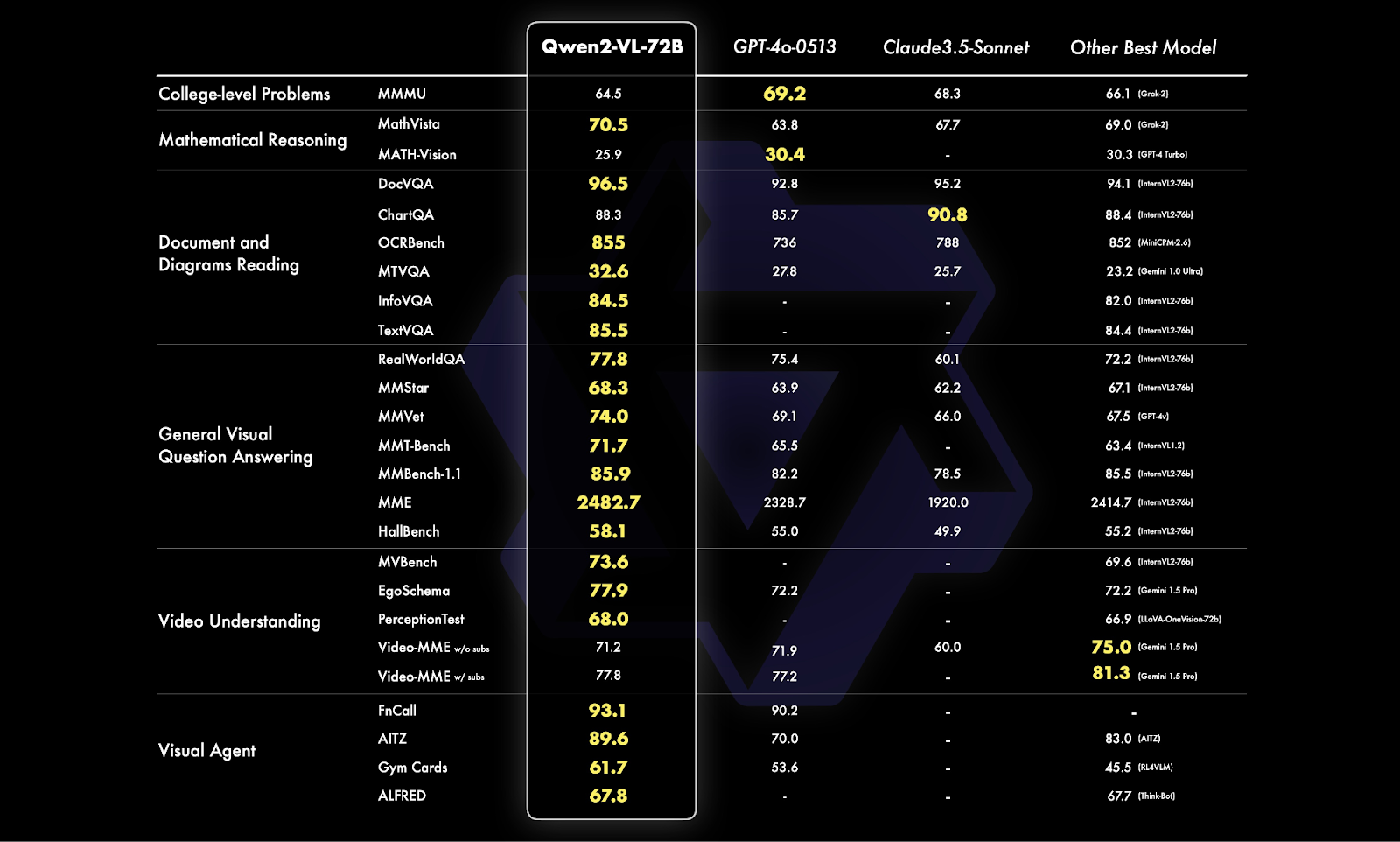
Qwen2-VL performs exceptionally well in benchmarks like MathVista (for math reasoning), DocVQA (for document understanding), and RealWorldQA (for answering real-world questions using visual information).
The model can analyse videos longer than 20 minutes, provide detailed summaries, and answer questions about the content. Qwen2-VL can also function as a control agent, operating devices like mobile phones and robots using visual cues and text commands.
Interestingly, it can recognise and understand text in images across multiple languages, including European languages, Japanese, Korean, and Arabic, making it accessible to a global audience.
Check out the model here.
Key highlights:
One of the key architectural improvements in Qwen2-VL includes the implementation of Naive Dynamic Resolution support. The model can adapt to and process images of different sizes and clarity.
“Unlike its predecessor, Qwen2-VL can handle arbitrary image resolutions, mapping them into a dynamic number of visual tokens, thereby ensuring consistency between the model input and the inherent information in images,” said Binyuan Hui, the creator of OpenDevin and core maintainer at Qwen.
He said that this approach more closely mimics human visual perception, allowing the model to process images of any clarity or size.
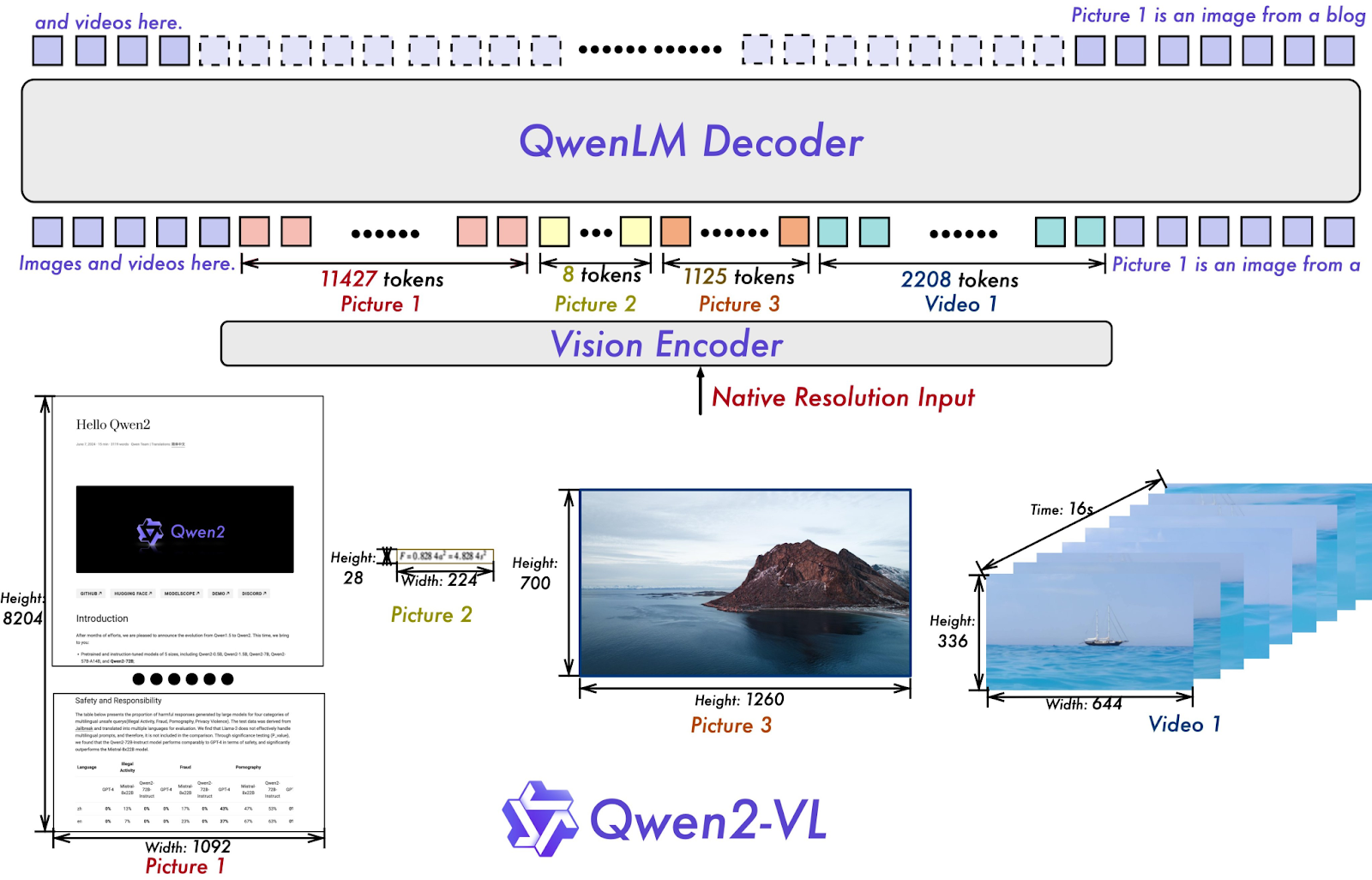
Another key architectural upgrade, according to Hui, is the innovation of Multimodal Rotary Position Embedding (M-ROPE). “By deconstructing the original rotary embedding into three parts representing temporal and spatial (height and width) information,M-ROPE enables LLM to concurrently capture and integrate 1D textual, 2D visual, and 3D video positional information,” he added.

In other words, this technique enables the model to understand and integrate text, image and video data. “Data is All You Need!” said Hui.
The use cases are plenty. William J.B. Mattingly, a digital nomad on X recently praised this development calling it his new favorite Handwritten Text Recognition (HTR) model while trying to convert a handwritten text into digital format.
Ashutosh Shrivastava a user on X used this model to solve a calculus problem and reported successful results for the same, proving its validity in problem solving.

Tanisha Bhattacharjee
Journalist with a passion for art, technological development and travel. Discovering the dynamic world of AI, one article at a time.



Association of Data Scientists
Tailored Generative AI Training for Your Team
Upcoming Large format Conference
Sep 25-27, 2024 | 📍 Bangalore, India
Download the easiest way to
stay informed


Subscribe to The Belamy: Our Weekly Newsletter
Biggest AI stories, delivered to your inbox every week.
Rising 2024 | DE&I in Tech Summit
April 4 and 5, 2024 | 📍 Hilton Convention Center, Manyata Tech Park, Bangalore
Data Engineering Summit 2024
May 30 and 31, 2024 | 📍 Bangalore, India
26 July 2024 | 583 Park Avenue, New York
MachineCon GCC Summit 2024
June 28 2024 | 📍Bangalore, India
Nov 21-22 2024 | 📍Santa Clara Convention Center, California, USA
September 25-27, 2024 | 📍Bangalore, India
![]()
Our Discord Community for AI Ecosystem, In collaboration with NVIDIA.


